Vypočítejte průměrnou hodnotu pomocí metody momentů. Průměr metodou momentů
Kde A je podmíněná nula rovna možnosti s maximální frekvencí (střed intervalu s maximální frekvencí), h je krok intervalu,
Účel služby. Pomocí online kalkulačky se průměrná hodnota vypočítá metodou momentů. Výsledek rozhodnutí je prezentován ve formátu Word.
Instrukce. Chcete-li získat řešení, musíte vyplnit počáteční údaje a vybrat parametry sestavy pro formátování ve Wordu.
Algoritmus pro zjištění průměru metodou momentů
Příklad. Pracovní doba strávená na homogenní technologické operaci byla rozdělena mezi pracovníky takto:
Je požadováno stanovení průměrného množství stráveného pracovního času a směrodatné odchylky pomocí metody momentů; variační koeficient; režim a medián.Tabulka pro výpočet ukazatelů.
| Skupiny | Střed intervalu, x i | Množství, f i | x i f i | Akumulovaná frekvence, S | (x-x) 2 f |
| 5 - 10 | 7.5 | 20 | 150 | 20 | 4600.56 |
| 15 - 20 | 17.5 | 25 | 437.5 | 45 | 667.36 |
| 20 - 25 | 22.5 | 50 | 1125 | 95 | 1.39 |
| 25 - 30 | 27.5 | 30 | 825 | 125 | 700.83 |
| 30 - 35 | 32.5 | 15 | 487.5 | 140 | 1450.42 |
| 35 - 40 | 37.5 | 10 | 375 | 150 | 2200.28 |
| 150 | 3400 | 9620.83 |
Móda
kde x 0 je začátek modálního intervalu; h – intervalová hodnota; f 2 – frekvence odpovídající modálnímu intervalu; f 1 – premodální frekvence; f 3 – postmodální frekvence.
Jako začátek intervalu zvolíme 20, protože tento interval obsahuje největší číslo.
Nejběžnější hodnota série je 22,78 minuty.
Medián
Medián je interval 20 - 25, protože v tomto intervalu je akumulovaná frekvence S větší než střední číslo (medián je první interval, jehož akumulovaná frekvence S přesahuje polovinu celkového součtu frekvencí).
Tedy 50 % jednotek v populaci bude mít méně než 23 min.
.
Najdeme A = 22,5, intervalový krok h = 5.
Střední kvadratické odchylky metodou momentů.
| x q | x*i | x * i f i | 2 f i |
| 7.5 | -3 | -60 | 180 |
| 17.5 | -1 | -25 | 25 |
| 22.5 | 0 | 0 | 0 |
| 27.5 | 1 | 30 | 30 |
| 32.5 | 2 | 30 | 60 |
| 37.5 | 3 | 30 | 90 |
| 5 | 385 |
Standardní odchylka.
min.
Variační koeficient- míra relativního rozptylu populačních hodnot: ukazuje, jaký podíl průměrné hodnoty této hodnoty tvoří její průměrný rozptyl.
Protože v>30 %, ale v<70%, то вариация умеренная.
Příklad
Pro vyhodnocení distribuční řady najdeme následující ukazatele:Vážený průměr
![]()
Průměrná hodnota studované charakteristiky podle metody momentů.
kde A je podmíněná nula rovna možnosti s maximální frekvencí (střed intervalu s maximální frekvencí), h je krok intervalu.
Variační rozsah (nebo rozsah variace) - to je rozdíl mezi maximální a minimální hodnotou charakteristiky:
V našem příkladu je rozsah variace ve směnném výkonu pracovníků: v první brigádě R = 105-95 = 10 dětí, ve druhé brigádě R = 125-75 = 50 dětí. (5krát více). To naznačuje, že výkon 1. brigády je „stabilnější“, ale druhá brigáda má větší rezervy na zvýšení výkonu, protože Pokud všichni pracovníci dosáhnou maximálního výkonu pro tuto brigádu, může vyrobit 3 * 125 = 375 dílů a v 1. brigádě pouze 105 * 3 = 315 dílů.
Pokud extrémní hodnoty charakteristiky nejsou pro populaci typické, použijí se kvartilové nebo decilové rozsahy. Kvartilový rozsah RQ= Q3-Q1 pokrývá 50 % objemu populace, první decilový rozsah RD1 = D9-D1 pokrývá 80 % dat, druhý decilový rozsah RD2= D8-D2 – 60 %.
Nevýhodou indikátoru variačního rozsahu je, že jeho hodnota neodráží všechny výkyvy znaku.
Nejjednodušší obecný ukazatel odrážející všechny výkyvy charakteristiky je průměrná lineární odchylka, což je aritmetický průměr absolutních odchylek jednotlivých opcí od jejich průměrné hodnoty:
,
pro seskupená data ![]() ,
,
kde xi je hodnota atributu v diskrétní řadě nebo střed intervalu v intervalovém rozdělení.
Ve výše uvedených vzorcích jsou rozdíly v čitateli brány modulo, jinak podle vlastnosti aritmetického průměru bude čitatel vždy roven nule. Proto se průměrná lineární odchylka ve statistické praxi používá jen zřídka, pouze v případech, kdy sčítání ukazatelů bez zohlednění znaménka dává ekonomický smysl. S jeho pomocí se analyzuje například složení pracovní síly, rentabilita výroby, obrat zahraničního obchodu.
Rozptyl vlastnosti je průměrná čtverec odchylek od jejich průměrné hodnoty:
jednoduchá variace ![]() ,
,
rozptyl vážený  .
.
Vzorec pro výpočet rozptylu lze zjednodušit:
Rozptyl se tedy rovná rozdílu mezi průměrem druhých mocnin opce a druhou mocninou průměru opce populace:  .
.
Vzhledem k součtu kvadrátů odchylek však rozptyl poskytuje zkreslenou představu o odchylkách, takže průměr se vypočítává na jeho základě standardní odchylka, který ukazuje, jak moc se v průměru konkrétní varianty znaku odchylují od své průměrné hodnoty. Vypočteno jako odmocnina z rozptylu:
pro neseskupená data 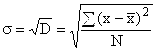 ,
,
pro variační série 
Čím menší je hodnota rozptylu a směrodatné odchylky, čím je populace homogennější, tím spolehlivější (typická) bude průměrná hodnota.
Průměrná lineární a směrodatná odchylka jsou pojmenovaná čísla, to znamená, že jsou vyjádřeny v měrných jednotkách charakteristiky, jsou obsahově shodné a významově blízké.
Doporučuje se vypočítat absolutní odchylky pomocí tabulek.
Tabulka 3 - Výpočet variačních charakteristik (na příkladu období údajů o směnovém výkonu pracovníků posádky)
Počet pracovníků |
Střed intervalu |
Vypočítané hodnoty |
|||||
Celkový: |
|||||||
Průměrný směnný výkon pracovníků: ![]()
Průměrná lineární odchylka: ![]()
Výrobní odchylka: 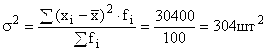
Směrodatná odchylka výkonu jednotlivých pracovníků od průměrného výkonu:
.
1 Výpočet rozptylu metodou momentů
Výpočet rozptylů zahrnuje těžkopádné výpočty (zejména pokud je průměr vyjádřen jako velké číslo s několika desetinnými místy). Výpočty lze zjednodušit použitím zjednodušeného vzorce a disperzních vlastností.
Disperze má následující vlastnosti:
- Pokud se všechny hodnoty charakteristiky sníží nebo zvýší o stejnou hodnotu A, pak se rozptyl nesníží:
 ,
,
 , pak nebo
, pak nebo 
Pomocí vlastností disperze a nejprve zmenšením všech variant populace o hodnotu A a následným dělením hodnotou intervalu h získáme vzorec pro výpočet disperze ve variačních řadách se stejnými intervaly způsobem: ,
,
kde je rozptyl vypočten pomocí metody momentů;
h – hodnota intervalu variační řady;
– možnost nové (transformované) hodnoty;
A je konstantní hodnota, která se používá jako střed intervalu s nejvyšší frekvencí; nebo možnost s nejvyšší frekvencí; 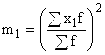 – druhá mocnina okamžiku prvního řádu;
– druhá mocnina okamžiku prvního řádu;
– okamžik druhého řádu.
Vypočítejme rozptyl pomocí metody momentů na základě údajů o směnovém výkonu pracovníků týmu.
Tabulka 4 - Výpočet rozptylu metodou momentů
Skupiny výrobních dělníků, ks. |
Počet pracovníků |
Střed intervalu |
Vypočítané hodnoty |
||
Postup výpočtu:


- Vypočítáme rozptyl:
2 Výpočet rozptylu alternativní charakteristiky
Mezi charakteristikami zkoumanými statistikou jsou i takové, které mají pouze dva vzájemně se vylučující významy. Toto jsou alternativní znamení. Jsou jim dány dvě kvantitativní hodnoty: možnosti 1 a 0. Četnost možnosti 1, která je označena p, je podíl jednotek s touto charakteristikou. Rozdíl 1-р=q je četnost možností 0.
xi |
|
Aritmetický průměr alternativního znaménka ![]() , protože p+q=1.
, protože p+q=1.
Alternativní rozptyl vlastností
, protože 1-R=q
Rozptyl alternativní charakteristiky je tedy roven součinu podílu jednotek s touto charakteristikou a podílu jednotek, které tuto charakteristiku nemají.
Pokud se hodnoty 1 a 0 vyskytují stejně často, tj. p=q, rozptyl dosahuje svého maxima pq=0,25.
Rozptyl alternativního atributu se používá ve výběrových šetřeních, například kvality produktu.
3 Rozdíl mezi skupinami. Pravidlo sčítání odchylek
Disperze, na rozdíl od jiných charakteristik variace, je aditivní veličina. Tedy v agregaci, která je rozdělena do skupin podle faktorových charakteristik X , rozptyl výsledné charakteristiky y lze rozložit na rozptyl v rámci každé skupiny (uvnitř skupin) a rozptyl mezi skupinami (mezi skupinami). Poté, spolu se studiem variací vlastnosti v celé populaci jako celku, je možné studovat variace v každé skupině i mezi těmito skupinami.
Celkový rozptyl měří variace ve znaku na v celém rozsahu pod vlivem všech faktorů, které tuto odchylku (odchylky) způsobily. Je rovna střední kvadratické odchylce jednotlivých hodnot atributu na z velkého průměru a lze jej vypočítat jako jednoduchý nebo vážený rozptyl.
Meziskupinová odchylka charakterizuje variaci výsledného znaku na způsobené vlivem faktoru-znaménka X, která tvořila základ seskupení. Charakterizuje variaci skupinových průměrů a rovná se střední čtverci odchylek skupinových průměrů od celkového průměru:  ,
,
kde je aritmetický průměr i-té skupiny;
– počet jednotek v i-té skupině (četnost i-té skupiny);
– celkový průměr populace.
Rozptyl v rámci skupiny odráží náhodnou variaci, tj. tu část variace, která je způsobena vlivem nezapočítaných faktorů a nezávisí na faktoru-atributu, který tvoří základ seskupení. Charakterizuje variaci jednotlivých hodnot vzhledem ke skupinovým průměrům a rovná se střední kvadratické odchylce jednotlivých hodnot atributu na v rámci skupiny z aritmetického průměru této skupiny (průměr skupiny) a vypočítá se jako jednoduchý nebo vážený rozptyl pro každou skupinu: ![]() nebo
nebo ![]() ,
,
kde je počet jednotek ve skupině.
Na základě rozdílů v rámci skupiny pro každou skupinu lze určit celkový průměr rozptylů v rámci skupiny:
.
Vztah mezi třemi disperzemi se nazývá pravidla pro přidávání odchylek, podle kterého se celkový rozptyl rovná součtu rozptylu mezi skupinami a průměru rozptylů uvnitř skupiny:
Příklad. Při studiu vlivu tarifní kategorie (kvalifikace) pracovníků na úroveň produktivity jejich práce byly získány následující údaje.
Tabulka 5 – Rozdělení pracovníků podle průměrného hodinového výkonu.
№ p/p |
Pracovníci 4. kategorie |
Pracovníci 5. kategorie |
|||||
Výstup |
Výstup |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
V tomto příkladu jsou pracovníci rozděleni do dvou skupin podle charakteristik faktorů X– kvalifikace, které se vyznačují svou hodností. Výsledný rys — produkce — se mění jak pod jeho vlivem (meziskupinová variace), tak vlivem dalších náhodných faktorů (vnitroskupinová variace). Cílem je měřit tyto variace pomocí tří rozptylů: celkových, mezi skupinami a v rámci skupin. Empirický koeficient determinace ukazuje podíl variace ve výsledné charakteristice na pod vlivem faktoru znamení X. Zbytek celkové variace na způsobené změnami jiných faktorů.
V příkladu je empirický koeficient determinace: ![]() nebo 66,7 %,
nebo 66,7 %,
To znamená, že 66,7 % odchylek v produktivitě pracovníků je způsobeno rozdíly v kvalifikaci a 33,3 % je způsobeno vlivem jiných faktorů.
Empirický korelační vztah ukazuje úzkou souvislost mezi seskupením a výkonnostními charakteristikami. Vypočteno jako druhá odmocnina empirického koeficientu determinace:
Empirický korelační poměr, jako je , může nabývat hodnot od 0 do 1.
Pokud není spojení, pak =0. V tomto případě =0, to znamená, že průměry skupiny jsou si navzájem rovné a neexistuje žádná meziskupinová variace. To znamená, že seskupovací charakteristika - faktor neovlivňuje tvorbu obecné variace.
Pokud je spojení funkční, pak =1. V tomto případě je rozptyl průměrů skupiny roven celkovému rozptylu (), to znamená, že neexistuje žádná variace v rámci skupiny. To znamená, že seskupovací charakteristika zcela určuje variaci výsledné studované charakteristiky.
Čím blíže je hodnota korelačního poměru k jednotě, tím blíže, blíže funkční závislosti, je souvislost mezi charakteristikami.
Pro kvalitativní posouzení těsnosti souvislostí mezi charakteristikami se používají Chaddockovy vztahy.
V příkladu ![]() , což ukazuje na úzkou souvislost mezi produktivitou pracovníků a jejich kvalifikací.
, což ukazuje na úzkou souvislost mezi produktivitou pracovníků a jejich kvalifikací.
Metody výpočtu aritmetického průměru (jednoduchý a vážený aritmetický průměr, metodou momentů)
Stanovíme průměrné hodnoty:
Režim (Po) =11, protože tato možnost se vyskytuje nejčastěji ve variační řadě (p = 6).
Medián (Me) - pořadové číslo varianty zaujímající střední pozici = 23, toto místo ve variační řadě zaujímá varianta rovna 11. Aritmetický průměr (M) umožňuje nejúplněji charakterizovat průměrnou úroveň studovaný rys. Pro výpočet aritmetického průměru se používají dvě metody: metoda aritmetického průměru a metoda momentů.
Pokud je četnost výskytu každé možnosti ve variační řadě rovna 1, pak se jednoduchý aritmetický průměr vypočítá pomocí metody aritmetického průměru: M = .
Pokud se četnost výskytu varianty ve variační řadě liší od 1, pak se vážený aritmetický průměr vypočítá pomocí metody aritmetického průměru:
Podle metody momentů: A - podmíněný průměr,
M = A+ = 11 + = 10,4 d = V-A, A = Mo = 11
Pokud je počet možností v řadě variant větší než 30, vytvoří se seskupená řada. Vytvoření seskupené řady:
1) stanovení Vmin a Vmax Vmin=3, Vmax=20;
2) určení počtu skupin (podle tabulky);
3) výpočet intervalu mezi skupinami i = 3;
4) určení začátku a konce skupin;
5) určení četnosti varianty každé skupiny (tabulka 2).
tabulka 2
Metodika pro konstrukci seskupených řad
|
Doba trvání ošetření ve dnech |
|||||||
|
n=45 p=480 p=302 p=766 |
Výhodou seskupené variační řady je, že výzkumník nepracuje s každou možností, ale pouze s možnostmi, které jsou pro každou skupinu průměrné. To značně zjednodušuje výpočty průměru.
Hodnota konkrétní charakteristiky není pro všechny členy populace stejná, navzdory její relativní homogenitě. Tento rys statistické populace je charakterizován jednou ze skupinových vlastností obecné populace - rozmanitost vlastností. Vezměme například skupinu 12letých chlapců a změřme jejich výšku. Po výpočtech bude průměrná úroveň tohoto znaku 153 cm, ale průměr charakterizuje obecnou míru studovaného znaku. Mezi chlapci daného věku jsou chlapci s výškou 165 cm nebo 141 cm, čím více chlapců má jinou výšku než 153 cm, tím větší je různorodost této charakteristiky ve statistické populaci.
Statistiky nám umožňují charakterizovat tuto vlastnost podle následujících kritérií:
limit (lim),
amplituda (Amp),
standardní odchylka ( y) ,
variační koeficient (Cv).
Omezit určeno extrémními hodnotami varianty ve variační řadě:
lim=V min /V max
Amplituda (Amp) - rozdíl mezi extrémními možnostmi:
Amp=V max -V min
Tyto hodnoty berou v úvahu pouze rozmanitost extrémních variant a neumožňují získat informace o rozmanitosti znaku v souhrnu s přihlédnutím k jeho vnitřní struktuře. Proto lze tato kritéria použít k aproximaci charakteristik diverzity, zejména při malém počtu pozorování (n<30).
variační řada lékařská statistika
A – podmíněný průměr (opakuje se častěji než ostatní v řadě variací)
a – podmíněná odchylka od podmíněného průměru (hodnocení)
i – interval
Fáze 1 - určení středu skupin;
Fáze 2 – pořadí skupin: 0 je přiřazena skupině, ve které je četnost výskytu varianty nejvyšší. Tito. v tomto případě 7-11 (frekvence -32). Pořadí směrem nahoru z dané skupiny se provádí přidáním (-1). Dolů – zvýšení (+1).
Fáze 3 – stanovení podmíněného režimu (podmíněný průměr). A je střed modálního intervalu. V našem případě je modální interval 7-11, takže A = 9.
Fáze 4 – stanovení intervalu. Interval ve všech skupinách řady je stejný a roven 5. i = 5/
Fáze 5 – stanovení celkového počtu pozorování. n = ∑p = 103.
Získaná data dosadíme do vzorce:
Úkoly pro samostatnou práci
Pomocí dat ze seskupených variačních řad vypočítejte aritmetický průměr pomocí metody momentů.
Možnost 1
Možnost č. 2
Možnost #3
Možnost č. 4
Možnost #5
Možnost #6
Možnost č. 7
Možnost č. 8
Možnost č. 9
Možnost č. 10
Možnost č. 11
Možnost č. 12
Úkol č. 4 Určení modu a mediánu v neseskupené sérii variací s lichým počtem možností
Délka ústavní léčby nemocných dětí ve dnech: 15, 14, 18, 17, 16, 20, 19, 16, 14, 16, 17, 12, 18, 19, 20.
Chcete-li určit režim v sérii variací, klasifikace série není nutná. Před určením mediánu je však nutné seřadit variační řady vzestupně nebo sestupně.
12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20.
Režim = 16. Protože možnost 16 se vyskytuje nejvícekrát (3krát).
Pokud existuje několik variant s nejvyšší frekvencí výskytu, pak mohou být v sérii variací uvedeny dva nebo více režimů.
Medián v řadě s lichým číslem je určen vzorcem: 
8 je pořadové číslo mediánu v řazené řadě variant,
Že. Já = 17.
Úkol č. 5 Určení modu a mediánu v neseskupené sérii variací se sudým počtem možností.
Na základě údajů uvedených v úloze musíte najít režim a medián
Délka hospitalizace nemocných dětí ve dnech: 15, 14, 18, 17, 16, 20, 19, 16, 14, 16, 17, 12, 18, 19, 20, 11
Vytváříme seřazenou sérii variací:
11, 12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20
Máme dvě střední čísla 16 a 17. V tomto případě je medián nalezen jako aritmetický průměr mezi nimi. Já = 16,5.
4. Sudé a liché.
V sudých variačních řadách je součet četností nebo celkový počet pozorování vyjádřen sudým číslem, v lichých - lichým číslem.
5. Symetrické a asymetrické.
V symetrické řadě variací se všechny typy průměrných hodnot shodují nebo jsou si velmi blízké (režim, medián, aritmetický průměr).
V sanitární statistice se v závislosti na povaze studovaných jevů, na konkrétních úkolech a cílech statistického výzkumu, jakož i na obsahu pramenného materiálu. Používají se následující typy průměrů:
· strukturální průměry (modus, medián);
· aritmetický průměr;
· harmonický průměr;
· geometrický průměr;
· středně progresivní.
Móda (M o) - hodnota proměnné charakteristiky, která se častěji vyskytuje ve zkoumané populaci, tzn. možnost odpovídající nejvyšší frekvenci. Zjistí to přímo ze struktury variační řady, aniž by se uchýlili k jakýmkoli výpočtům. Obvykle je to hodnota velmi blízká aritmetickému průměru a v praxi je velmi vhodná.
Medián (M e) - rozdělení variační řady (seřazené, tj. hodnoty opce jsou uspořádány vzestupně nebo sestupně) na dvě stejné poloviny. Medián se vypočítá pomocí tzv. liché řady, která se získá sekvenčním sčítáním četností. Pokud součet frekvencí odpovídá sudému číslu, pak se jako medián obvykle bere aritmetický průměr dvou průměrných hodnot.
Modus a medián se používá v případě otevřené populace, tzn. kdy největší nebo nejmenší opce nemají přesnou kvantitativní charakteristiku (například do 15 let, 50 a více let atd.). V tomto případě nelze vypočítat aritmetický průměr (parametrické charakteristiky).
Průměrný Jsem aritmetik - nejběžnější hodnota. Aritmetický průměr se často označuje M.
Existují jednoduché a vážené aritmetické průměry.
Jednoduchý aritmetický průměr vypočítané:
- v případech, kdy je populace reprezentována jednoduchým seznamem znalostí charakteristiky pro každou jednotku;
- pokud nelze určit počet opakování každé možnosti;
- pokud je počet opakování každé možnosti blízko sobě.
Jednoduchý aritmetický průměr se vypočítá podle vzorce:
kde V - jednotlivé hodnoty charakteristiky; n - počet jednotlivých hodnot; - součtový znak.
Prostý průměr je tedy poměr součtu variant k počtu pozorování.
Příklad: určete průměrnou délku pobytu na lůžku pro 10 pacientů se zápalem plic:
16 dní - 1 pacient; 17–1; 18–1; 19–1; 20–1; 21–1; 22–1; 23–1; 26–1; 31–1.
postelový den
Aritmetický průměr vážený se počítá v případech, kdy se jednotlivé hodnoty charakteristiky opakují. Lze jej vypočítat dvěma způsoby:
1. Přímo (aritmetický průměr nebo přímá metoda) podle vzorce:
kde P je četnost (počet případů) pozorování každé možnosti.
Vážený aritmetický průměr je tedy poměr součtu součinů varianty a četnosti k počtu pozorování.
2. Výpočtem odchylek od podmíněného průměru (pomocí metody momentů).
Základem pro výpočet váženého aritmetického průměru je:
― seskupený materiál podle variant kvantitativní charakteristiky;
— všechny možnosti by měly být uspořádány vzestupně nebo sestupně podle hodnoty atributu (řazený řádek).
Pro výpočet pomocí momentové metody je předpokladem stejná velikost všech intervalů.
Pomocí metody momentů se aritmetický průměr vypočítá pomocí vzorce:
 ,
,
kde M o je podmíněný průměr, který se často považuje za hodnotu charakteristiky odpovídající nejvyšší frekvenci, tzn. která se častěji opakuje (Móda).
i je hodnota intervalu.
a je podmíněná odchylka od podmínek průměru, což je sekvenční řada čísel (1, 2 atd.) se znaménkem + pro varianty velkých podmíněných průměrů a se znaménkem – (–1, –2 atd.). .) pro varianty, které jsou pod konvenčním průměrem. Podmíněná odchylka od varianty brané jako podmíněný průměr je 0.
P - frekvence.
Celkový počet pozorování nebo n.
Příklad: určit průměrnou výšku 8letých chlapců přímo (tab. 1).
stůl 1
|
Výška v cm |
kluci P |
Centrální možnost V |
|
Centrální možnost - střed intervalu - je definována jako polosoučet počátečních hodnot dvou sousedních skupin:
![]() ;
; ![]() atd.
atd.
Součin VP se získá vynásobením centrálních variant frekvencemi; atd. Poté se přidají a získají výsledné produkty ![]() , který se vydělí počtem pozorování (100) a získá se vážený aritmetický průměr.
, který se vydělí počtem pozorování (100) a získá se vážený aritmetický průměr.
![]() cm.
cm.
Stejný problém vyřešíme pomocí metody momentů, pro kterou je sestavena následující tabulka 2:
Tabulka 2
|
Výška v cm (V) |
kluci P |
||
122 bereme jako M o, protože ze 100 pozorování mělo 33 lidí výšku 122 cm. Najdeme podmíněné odchylky (a) od podmíněného průměru v souladu s výše uvedeným. Poté získáme součin podmíněných odchylek a frekvencí (aP) a sečteme získané hodnoty (). Výsledek je 17. Nakonec dosadíme data do vzorce.