നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് ശരാശരി മൂല്യം കണക്കാക്കുക. നിമിഷങ്ങളുടെ രീതി പ്രകാരം ശരാശരി
പരമാവധി ആവൃത്തിയുള്ള (പരമാവധി ആവൃത്തിയുള്ള ഇടവേളയുടെ മധ്യഭാഗം) ഓപ്ഷന് തുല്യമായ ഒരു സോപാധിക പൂജ്യം A ആണെങ്കിൽ, h ആണ് ഇടവേള ഘട്ടം,
സേവനത്തിന്റെ ഉദ്ദേശ്യം. ഒരു ഓൺലൈൻ കാൽക്കുലേറ്റർ ഉപയോഗിച്ച്, മൊമെന്റുകളുടെ രീതി ഉപയോഗിച്ച് ശരാശരി മൂല്യം കണക്കാക്കുന്നു. തീരുമാനത്തിന്റെ ഫലം Word ഫോർമാറ്റിൽ അവതരിപ്പിച്ചിരിക്കുന്നു.
നിർദ്ദേശങ്ങൾ. ഒരു പരിഹാരം ലഭിക്കുന്നതിന്, നിങ്ങൾ പ്രാരംഭ ഡാറ്റ പൂരിപ്പിച്ച് Word-ൽ ഫോർമാറ്റിംഗിനായി റിപ്പോർട്ട് പാരാമീറ്ററുകൾ തിരഞ്ഞെടുക്കേണ്ടതുണ്ട്.
നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് ശരാശരി കണ്ടെത്തുന്നതിനുള്ള അൽഗോരിതം
ഉദാഹരണം. ഒരു ഏകീകൃത സാങ്കേതിക പ്രവർത്തനത്തിനായി ചെലവഴിച്ച തൊഴിൽ സമയം ഇനിപ്പറയുന്ന രീതിയിൽ തൊഴിലാളികൾക്കിടയിൽ വിതരണം ചെയ്തു:
നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് ചെലവഴിച്ച ജോലി സമയത്തിന്റെ ശരാശരി അളവും സ്റ്റാൻഡേർഡ് ഡീവിയേഷനും നിർണ്ണയിക്കേണ്ടത് ആവശ്യമാണ്; വ്യതിയാനത്തിന്റെ ഗുണകം; മോഡും മീഡിയനും.സൂചകങ്ങൾ കണക്കാക്കുന്നതിനുള്ള പട്ടിക.
| ഗ്രൂപ്പുകൾ | ഇടവേളയുടെ മധ്യഭാഗം, x i | അളവ്, f i | x i f i | സഞ്ചിത ആവൃത്തി, എസ് | (x-x) 2 f |
| 5 - 10 | 7.5 | 20 | 150 | 20 | 4600.56 |
| 15 - 20 | 17.5 | 25 | 437.5 | 45 | 667.36 |
| 20 - 25 | 22.5 | 50 | 1125 | 95 | 1.39 |
| 25 - 30 | 27.5 | 30 | 825 | 125 | 700.83 |
| 30 - 35 | 32.5 | 15 | 487.5 | 140 | 1450.42 |
| 35 - 40 | 37.5 | 10 | 375 | 150 | 2200.28 |
| 150 | 3400 | 9620.83 |
ഫാഷൻ
ഇവിടെ x 0 എന്നത് മോഡൽ ഇടവേളയുടെ തുടക്കമാണ്; h - ഇടവേള മൂല്യം; f 2 - മോഡൽ ഇടവേളയുമായി ബന്ധപ്പെട്ട ആവൃത്തി; f 1 - പ്രീമോഡൽ ആവൃത്തി; f 3 - പോസ്റ്റ്മോഡൽ ആവൃത്തി.
ഈ ഇടവേളയിൽ ഏറ്റവും വലിയ സംഖ്യ അടങ്ങിയിരിക്കുന്നതിനാൽ, ഇടവേളയുടെ തുടക്കമായി ഞങ്ങൾ 20 തിരഞ്ഞെടുക്കുന്നു.
പരമ്പരയുടെ ഏറ്റവും സാധാരണമായ മൂല്യം 22.78 മിനിറ്റാണ്.
മീഡിയൻ
മീഡിയൻ ഇടവേള 20 - 25 ആണ്, കാരണം ഈ ഇടവേളയിൽ, സഞ്ചിത ഫ്രീക്വൻസി എസ് ശരാശരി സംഖ്യയേക്കാൾ കൂടുതലാണ് (മധ്യസ്ഥം എന്നത് ആദ്യത്തെ ഇടവേളയാണ്, അതിന്റെ സഞ്ചിത ആവൃത്തി S മൊത്തം ആവൃത്തികളുടെ പകുതിയിലധികം കവിയുന്നു).
അങ്ങനെ, ജനസംഖ്യയിലെ 50% യൂണിറ്റുകളും 23 മിനിറ്റിൽ കുറവായിരിക്കും.
.
ഞങ്ങൾ A = 22.5, ഇടവേള ഘട്ടം h = 5 കണ്ടെത്തുന്നു.
മൊമെന്റുകളുടെ രീതി ഉപയോഗിച്ച് ശരാശരി ചതുര വ്യതിയാനങ്ങൾ.
| x q | x*i | x * i f i | 2 f i |
| 7.5 | -3 | -60 | 180 |
| 17.5 | -1 | -25 | 25 |
| 22.5 | 0 | 0 | 0 |
| 27.5 | 1 | 30 | 30 |
| 32.5 | 2 | 30 | 60 |
| 37.5 | 3 | 30 | 90 |
| 5 | 385 |
സ്റ്റാൻഡേർഡ് ഡീവിയേഷൻ.
മിനിറ്റ്
വ്യതിയാനത്തിന്റെ ഗുണകം- ജനസംഖ്യാ മൂല്യങ്ങളുടെ ആപേക്ഷിക വ്യാപനത്തിന്റെ അളവ്: ഈ മൂല്യത്തിന്റെ ശരാശരി മൂല്യത്തിന്റെ എത്ര അനുപാതമാണ് അതിന്റെ ശരാശരി വ്യാപനമെന്ന് കാണിക്കുന്നു.
v>30% മുതൽ, എന്നാൽ v<70%, то вариация умеренная.
ഉദാഹരണം
വിതരണ ശ്രേണി വിലയിരുത്തുന്നതിന്, ഞങ്ങൾ ഇനിപ്പറയുന്ന സൂചകങ്ങൾ കണ്ടെത്തുന്നു:ശരാശരി തൂക്കം
![]()
നിമിഷങ്ങളുടെ രീതി അനുസരിച്ച് പഠിച്ച സ്വഭാവത്തിന്റെ ശരാശരി മൂല്യം.
പരമാവധി ആവൃത്തിയുള്ള (പരമാവധി ആവൃത്തിയുള്ള ഇടവേളയുടെ മധ്യഭാഗം) ഓപ്ഷന് തുല്യമായ സോപാധിക പൂജ്യമാണ് A എന്നത് ഇടവേള ഘട്ടമാണ്.
വ്യതിയാന ശ്രേണി (അല്ലെങ്കിൽ വ്യതിയാനത്തിന്റെ പരിധി) -സ്വഭാവത്തിന്റെ പരമാവധി, കുറഞ്ഞ മൂല്യങ്ങൾ തമ്മിലുള്ള വ്യത്യാസം ഇതാണ്:
ഞങ്ങളുടെ ഉദാഹരണത്തിൽ, തൊഴിലാളികളുടെ ഷിഫ്റ്റ് ഔട്ട്പുട്ടിലെ വ്യത്യാസത്തിന്റെ പരിധി ഇതാണ്: ആദ്യ ബ്രിഗേഡിൽ R = 105-95 = 10 കുട്ടികൾ, രണ്ടാമത്തെ ബ്രിഗേഡിൽ R = 125-75 = 50 കുട്ടികൾ. (5 മടങ്ങ് കൂടുതൽ). ഒന്നാം ബ്രിഗേഡിന്റെ ഔട്ട്പുട്ട് കൂടുതൽ “സ്ഥിരത” ഉള്ളതാണെന്ന് ഇത് സൂചിപ്പിക്കുന്നു, എന്നാൽ രണ്ടാമത്തെ ബ്രിഗേഡിന് ഉൽപാദനം വർദ്ധിപ്പിക്കുന്നതിന് കൂടുതൽ കരുതൽ ഉണ്ട്, കാരണം എല്ലാ തൊഴിലാളികളും ഈ ബ്രിഗേഡിനായി പരമാവധി ഔട്ട്പുട്ടിൽ എത്തിയാൽ, അതിന് 3 * 125 = 375 ഭാഗങ്ങൾ ഉൽപ്പാദിപ്പിക്കാൻ കഴിയും, കൂടാതെ ഒന്നാം ബ്രിഗേഡിൽ 105 * 3 = 315 ഭാഗങ്ങൾ മാത്രം.
ഒരു സ്വഭാവത്തിന്റെ അങ്ങേയറ്റത്തെ മൂല്യങ്ങൾ ജനസംഖ്യയ്ക്ക് സാധാരണമല്ലെങ്കിൽ, ക്വാർട്ടൈൽ അല്ലെങ്കിൽ ഡെസിൽ ശ്രേണികൾ ഉപയോഗിക്കുന്നു. ക്വാർട്ടൈൽ ശ്രേണി RQ= Q3-Q1 ജനസംഖ്യയുടെ 50% ഉൾക്കൊള്ളുന്നു, ആദ്യ ഡെസിൽ ശ്രേണി RD1 = D9-D1 ഡാറ്റയുടെ 80% ഉൾക്കൊള്ളുന്നു, രണ്ടാമത്തെ ദശാംശ ശ്രേണി RD2= D8-D2 - 60%.
വ്യതിയാന ശ്രേണി സൂചകത്തിന്റെ പോരായ്മ അതിന്റെ മൂല്യം സ്വഭാവത്തിന്റെ എല്ലാ ഏറ്റക്കുറച്ചിലുകളും പ്രതിഫലിപ്പിക്കുന്നില്ല എന്നതാണ്.
ഒരു സ്വഭാവത്തിന്റെ എല്ലാ ഏറ്റക്കുറച്ചിലുകളും പ്രതിഫലിപ്പിക്കുന്ന ഏറ്റവും ലളിതമായ പൊതു സൂചകം ശരാശരി രേഖീയ വ്യതിയാനം, വ്യക്തിഗത ഓപ്ഷനുകളുടെ ശരാശരി മൂല്യത്തിൽ നിന്നുള്ള കേവല വ്യതിയാനങ്ങളുടെ ഗണിത ശരാശരിയാണ്:
,
ഗ്രൂപ്പുചെയ്ത ഡാറ്റയ്ക്കായി ![]() ,
,
ഇവിടെ xi എന്നത് ഒരു വ്യതിരിക്ത ശ്രേണിയിലെ ആട്രിബ്യൂട്ടിന്റെ മൂല്യമാണ് അല്ലെങ്കിൽ ഇടവേള വിതരണത്തിലെ ഇടവേളയുടെ മധ്യമാണ്.
മുകളിലുള്ള സൂത്രവാക്യങ്ങളിൽ, ന്യൂമറേറ്ററിലെ വ്യത്യാസങ്ങൾ മൊഡ്യൂളായി എടുക്കുന്നു, അല്ലാത്തപക്ഷം, ഗണിത ശരാശരിയുടെ സ്വത്ത് അനുസരിച്ച്, ന്യൂമറേറ്റർ എല്ലായ്പ്പോഴും പൂജ്യത്തിന് തുല്യമായിരിക്കും. അതിനാൽ, ശരാശരി രേഖീയ വ്യതിയാനം സ്ഥിതിവിവരക്കണക്കിൽ വളരെ അപൂർവമായി മാത്രമേ ഉപയോഗിക്കൂ, ചിഹ്നം കണക്കിലെടുക്കാതെ സൂചകങ്ങൾ സംഗ്രഹിക്കുന്നത് സാമ്പത്തിക അർത്ഥമുള്ള സന്ദർഭങ്ങളിൽ മാത്രം. അതിന്റെ സഹായത്തോടെ, ഉദാഹരണത്തിന്, തൊഴിലാളികളുടെ ഘടന, ഉൽപാദനത്തിന്റെ ലാഭക്ഷമത, വിദേശ വ്യാപാര വിറ്റുവരവ് എന്നിവ വിശകലനം ചെയ്യുന്നു.
ഒരു സ്വഭാവത്തിന്റെ വ്യത്യാസംഅവയുടെ ശരാശരി മൂല്യത്തിൽ നിന്നുള്ള വ്യതിയാനങ്ങളുടെ ശരാശരി ചതുരം:
ലളിതമായ വ്യത്യാസം ![]() ,
,
വേരിയൻസ് വെയ്റ്റഡ്  .
.
വ്യത്യാസം കണക്കാക്കുന്നതിനുള്ള സൂത്രവാക്യം ലളിതമാക്കാം:
അങ്ങനെ, വ്യതിയാനം, ഓപ്ഷന്റെ സ്ക്വയറുകളുടെ ശരാശരിയും ജനസംഖ്യയുടെ ഓപ്ഷന്റെ ശരാശരിയുടെ വർഗ്ഗവും തമ്മിലുള്ള വ്യത്യാസത്തിന് തുല്യമാണ്:  .
.
എന്നിരുന്നാലും, ചതുരാകൃതിയിലുള്ള വ്യതിയാനങ്ങളുടെ സംഗ്രഹം കാരണം, വ്യതിയാനം വ്യതിയാനങ്ങളെക്കുറിച്ച് ഒരു വികലമായ ആശയം നൽകുന്നു, അതിനാൽ ശരാശരി കണക്കാക്കുന്നത് അതിനെ അടിസ്ഥാനമാക്കിയാണ്. സ്റ്റാൻഡേർഡ് ഡീവിയേഷൻ, ഒരു സ്വഭാവത്തിന്റെ ശരാശരി നിർദ്ദിഷ്ട വകഭേദങ്ങൾ അവയുടെ ശരാശരി മൂല്യത്തിൽ നിന്ന് എത്രമാത്രം വ്യതിചലിക്കുന്നുവെന്ന് കാണിക്കുന്നു. വ്യതിയാനത്തിന്റെ വർഗ്ഗമൂലമെടുത്ത് കണക്കാക്കുന്നു:
ഗ്രൂപ്പ് ചെയ്യാത്ത ഡാറ്റയ്ക്ക് 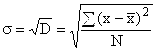 ,
,
വ്യതിയാന പരമ്പരകൾക്കായി 
വ്യതിയാനത്തിന്റെയും സ്റ്റാൻഡേർഡ് ഡീവിയേഷന്റെയും ചെറിയ മൂല്യം, കൂടുതൽ ഏകതാനമായ ജനസംഖ്യ, കൂടുതൽ വിശ്വസനീയമായ (സാധാരണ) ശരാശരി മൂല്യം ആയിരിക്കും.
ശരാശരി രേഖീയവും സ്റ്റാൻഡേർഡ് ഡീവിയേഷനും സംഖ്യകൾ എന്ന് പേരിട്ടിരിക്കുന്നു, അതായത് അവ ഒരു സ്വഭാവത്തിന്റെ അളവെടുപ്പ് യൂണിറ്റുകളിൽ പ്രകടിപ്പിക്കുന്നു, ഉള്ളടക്കത്തിൽ സമാനവും അർത്ഥത്തിൽ അടുത്തും ആണ്.
പട്ടികകൾ ഉപയോഗിച്ച് സമ്പൂർണ്ണ വ്യതിയാനങ്ങൾ കണക്കാക്കാൻ ശുപാർശ ചെയ്യുന്നു.
പട്ടിക 3 - വ്യതിയാന സ്വഭാവങ്ങളുടെ കണക്കുകൂട്ടൽ (ക്രൂ തൊഴിലാളികളുടെ ഷിഫ്റ്റ് ഔട്ട്പുട്ടിലെ ഡാറ്റയുടെ കാലഘട്ടത്തിന്റെ ഉദാഹരണം ഉപയോഗിച്ച്)
തൊഴിലാളികളുടെ എണ്ണം |
ഇടവേളയുടെ മധ്യഭാഗം |
കണക്കാക്കിയ മൂല്യങ്ങൾ |
|||||
ആകെ: |
|||||||
തൊഴിലാളികളുടെ ശരാശരി ഷിഫ്റ്റ് ഔട്ട്പുട്ട്: ![]()
ശരാശരി രേഖീയ വ്യതിയാനം: ![]()
ഉൽപ്പാദന വ്യത്യാസം: 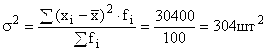
ശരാശരി ഔട്ട്പുട്ടിൽ നിന്ന് വ്യക്തിഗത തൊഴിലാളികളുടെ ഔട്ട്പുട്ടിന്റെ സ്റ്റാൻഡേർഡ് ഡീവിയേഷൻ:
.
1 നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് ചിതറിക്കിടക്കുന്നതിന്റെ കണക്കുകൂട്ടൽ
വ്യതിയാനങ്ങൾ കണക്കാക്കുന്നത് ബുദ്ധിമുട്ടുള്ള കണക്കുകൂട്ടലുകൾ ഉൾക്കൊള്ളുന്നു (പ്രത്യേകിച്ച് ശരാശരി നിരവധി ദശാംശ സ്ഥാനങ്ങളുള്ള ഒരു വലിയ സംഖ്യയായി പ്രകടിപ്പിക്കുകയാണെങ്കിൽ). ലളിതമായ ഫോർമുലയും ഡിസ്പർഷൻ പ്രോപ്പർട്ടിയും ഉപയോഗിച്ച് കണക്കുകൂട്ടലുകൾ ലളിതമാക്കാം.
വിതരണത്തിന് ഇനിപ്പറയുന്ന ഗുണങ്ങളുണ്ട്:
- ഒരു സ്വഭാവസവിശേഷതയുടെ എല്ലാ മൂല്യങ്ങളും ഒരേ മൂല്യം A കൊണ്ട് കുറയ്ക്കുകയോ വർദ്ധിപ്പിക്കുകയോ ചെയ്താൽ, ചിതറൽ കുറയുകയില്ല:
 ,
,
 , പിന്നെ അല്ലെങ്കിൽ
, പിന്നെ അല്ലെങ്കിൽ 
ചിതറിക്കിടക്കുന്നതിന്റെ ഗുണവിശേഷതകൾ ഉപയോഗിച്ച് ആദ്യം പോപ്പുലേഷന്റെ എല്ലാ വകഭേദങ്ങളും മൂല്യം A കൊണ്ട് കുറയ്ക്കുക, തുടർന്ന് h ഇടവേളയുടെ മൂല്യം കൊണ്ട് ഹരിക്കുക, തുല്യ ഇടവേളകളുള്ള വേരിയേഷൻ ശ്രേണിയിലെ ചിതറിക്കൽ കണക്കാക്കുന്നതിനുള്ള ഒരു ഫോർമുല നമുക്ക് ലഭിക്കും. ഒരു വിധത്തിൽ: ,
,
നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് ചിതറിക്കിടക്കുന്നത് എവിടെയാണ് കണക്കാക്കുന്നത്;
h - വ്യതിയാന പരമ്പരയുടെ ഇടവേളയുടെ മൂല്യം;
- പുതിയ (രൂപാന്തരപ്പെട്ട) മൂല്യങ്ങളുടെ ഓപ്ഷൻ;
എ എന്നത് ഒരു സ്ഥിരമായ മൂല്യമാണ്, ഇത് ഏറ്റവും ഉയർന്ന ആവൃത്തിയുള്ള ഇടവേളയുടെ മധ്യമായി ഉപയോഗിക്കുന്നു; അല്ലെങ്കിൽ ഏറ്റവും ഉയർന്ന ആവൃത്തിയുള്ള ഓപ്ഷൻ; 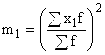 - ആദ്യ ഓർഡർ നിമിഷത്തിന്റെ ചതുരം;
- ആദ്യ ഓർഡർ നിമിഷത്തിന്റെ ചതുരം;
- രണ്ടാമത്തെ ഓർഡറിന്റെ നിമിഷം.
ടീമിന്റെ തൊഴിലാളികളുടെ ഷിഫ്റ്റ് ഔട്ട്പുട്ടിലെ ഡാറ്റയെ അടിസ്ഥാനമാക്കി നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് നമുക്ക് ഡിസ്പർഷൻ കണക്കാക്കാം.
പട്ടിക 4 - നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് വ്യത്യാസത്തിന്റെ കണക്കുകൂട്ടൽ
ഉൽപ്പാദന തൊഴിലാളികളുടെ ഗ്രൂപ്പുകൾ, പിസികൾ. |
തൊഴിലാളികളുടെ എണ്ണം |
ഇടവേളയുടെ മധ്യഭാഗം |
കണക്കാക്കിയ മൂല്യങ്ങൾ |
||
കണക്കുകൂട്ടൽ നടപടിക്രമം:


- ഞങ്ങൾ വ്യത്യാസം കണക്കാക്കുന്നു:
2 ഒരു ഇതര സ്വഭാവത്തിന്റെ വ്യതിയാനത്തിന്റെ കണക്കുകൂട്ടൽ
സ്ഥിതിവിവരക്കണക്കുകൾ പഠിക്കുന്ന സ്വഭാവസവിശേഷതകളിൽ, പരസ്പരവിരുദ്ധമായ രണ്ട് അർത്ഥങ്ങൾ മാത്രമുള്ളവയും ഉണ്ട്. ഇവ ബദൽ അടയാളങ്ങളാണ്. അവയ്ക്ക് യഥാക്രമം രണ്ട് ക്വാണ്ടിറ്റേറ്റീവ് മൂല്യങ്ങൾ നൽകിയിരിക്കുന്നു: ഓപ്ഷനുകൾ 1 ഉം 0 ഉം. ഓപ്ഷൻ 1 ന്റെ ഫ്രീക്വൻസി, ഇത് p കൊണ്ട് സൂചിപ്പിച്ചിരിക്കുന്നു, ഈ സ്വഭാവം ഉള്ള യൂണിറ്റുകളുടെ അനുപാതമാണ്. വ്യത്യാസം 1-р=q എന്നത് ഓപ്ഷനുകളുടെ ആവൃത്തിയാണ് 0. അങ്ങനെ,
xi |
|
ഇതര ചിഹ്നത്തിന്റെ ഗണിത ശരാശരി ![]() , കാരണം p+q=1.
, കാരണം p+q=1.
ഇതര സ്വഭാവ വ്യതിയാനം
, കാരണം 1-р=ക്യു
അതിനാൽ, ഒരു ഇതര സ്വഭാവത്തിന്റെ വ്യത്യാസം ഈ സ്വഭാവം ഉള്ള യൂണിറ്റുകളുടെ അനുപാതത്തിന്റെയും ഈ സ്വഭാവം ഇല്ലാത്ത യൂണിറ്റുകളുടെ അനുപാതത്തിന്റെയും ഗുണനത്തിന് തുല്യമാണ്.
മൂല്യങ്ങൾ 1 ഉം 0 ഉം തുല്യമായി സംഭവിക്കുകയാണെങ്കിൽ, അതായത് p=q, വ്യതിയാനം അതിന്റെ പരമാവധി pq=0.25 ൽ എത്തുന്നു.
ഒരു ഇതര ആട്രിബ്യൂട്ടിന്റെ വ്യത്യാസം സാമ്പിൾ സർവേകളിൽ ഉപയോഗിക്കുന്നു, ഉദാഹരണത്തിന്, ഉൽപ്പന്ന ഗുണനിലവാരം.
3 ഗ്രൂപ്പ് വ്യത്യാസം. വേരിയൻസ് കൂട്ടിച്ചേർക്കൽ നിയമം
വ്യതിരിക്തത, വ്യതിയാനത്തിന്റെ മറ്റ് സവിശേഷതകളിൽ നിന്ന് വ്യത്യസ്തമായി, ഒരു സങ്കലന അളവാണ്. അതായത്, ഫാക്ടർ സ്വഭാവസവിശേഷതകൾ അനുസരിച്ച് ഗ്രൂപ്പുകളായി വിഭജിച്ചിരിക്കുന്ന മൊത്തത്തിൽ എക്സ് , ഫലമായുണ്ടാകുന്ന സ്വഭാവത്തിന്റെ വ്യത്യാസം വൈഓരോ ഗ്രൂപ്പിനുള്ളിലെയും (ഗ്രൂപ്പുകൾക്കുള്ളിൽ) ഗ്രൂപ്പുകൾക്കിടയിലുള്ള വ്യത്യാസത്തിലേക്കും (ഗ്രൂപ്പുകൾക്കിടയിൽ) വിഘടിപ്പിക്കാം. തുടർന്ന്, മുഴുവൻ ജനസംഖ്യയിലും മൊത്തത്തിൽ ഒരു സ്വഭാവത്തിന്റെ വ്യതിയാനം പഠിക്കുന്നതിനൊപ്പം, ഓരോ ഗ്രൂപ്പിലും ഈ ഗ്രൂപ്പുകൾക്കിടയിലും ഉള്ള വ്യതിയാനം പഠിക്കാൻ കഴിയും.
ആകെ വ്യത്യാസംഒരു സ്വഭാവത്തിലെ വ്യതിയാനം അളക്കുന്നു ചെയ്തത്ഈ വ്യതിയാനത്തിന് (വ്യതിയാനങ്ങൾ) കാരണമായ എല്ലാ ഘടകങ്ങളുടെയും സ്വാധീനത്തിൽ പൂർണ്ണമായും. ഇത് ആട്രിബ്യൂട്ടിന്റെ വ്യക്തിഗത മൂല്യങ്ങളുടെ ശരാശരി ചതുര വ്യതിയാനത്തിന് തുല്യമാണ് ചെയ്തത്ഗ്രാൻഡ് ആവറേജിൽ നിന്ന്, ലളിതമോ തൂക്കമുള്ളതോ ആയ വ്യത്യാസമായി കണക്കാക്കാം.
ഇന്റർഗ്രൂപ്പ് വേരിയൻസ്തത്ഫലമായുണ്ടാകുന്ന സ്വഭാവത്തിന്റെ വ്യതിയാനത്തെ ചിത്രീകരിക്കുന്നു ചെയ്തത്ഘടകം-ചിഹ്നത്തിന്റെ സ്വാധീനത്താൽ സംഭവിക്കുന്നത് എക്സ്, ഇത് ഗ്രൂപ്പിംഗിന്റെ അടിസ്ഥാനമായി. ഇത് ഗ്രൂപ്പ് ശരാശരികളുടെ വ്യതിയാനത്തെ ചിത്രീകരിക്കുന്നു, മൊത്തത്തിലുള്ള ശരാശരിയിൽ നിന്ന് ഗ്രൂപ്പ് ശരാശരികളുടെ വ്യതിയാനങ്ങളുടെ ശരാശരി ചതുരത്തിന് തുല്യമാണ്:  ,
,
i-th ഗ്രൂപ്പിന്റെ ഗണിത ശരാശരി എവിടെയാണ്;
- i-th ഗ്രൂപ്പിലെ യൂണിറ്റുകളുടെ എണ്ണം (i-th ഗ്രൂപ്പിന്റെ ആവൃത്തി);
- ജനസംഖ്യയുടെ മൊത്തത്തിലുള്ള ശരാശരി.
ഗ്രൂപ്പിനുള്ളിലെ വ്യത്യാസംക്രമരഹിതമായ വ്യതിയാനത്തെ പ്രതിഫലിപ്പിക്കുന്നു, അതായത്, കണക്കാക്കാത്ത ഘടകങ്ങളുടെ സ്വാധീനം മൂലമുണ്ടാകുന്ന വ്യതിയാനത്തിന്റെ ഭാഗം, ഗ്രൂപ്പിംഗിന്റെ അടിസ്ഥാനമായ ഘടകം-ആട്രിബ്യൂട്ടിനെ ആശ്രയിക്കുന്നില്ല. ഇത് ഗ്രൂപ്പ് ശരാശരിയുമായി താരതമ്യപ്പെടുത്തുമ്പോൾ വ്യക്തിഗത മൂല്യങ്ങളുടെ വ്യതിയാനത്തെ ചിത്രീകരിക്കുന്നു, ആട്രിബ്യൂട്ടിന്റെ വ്യക്തിഗത മൂല്യങ്ങളുടെ ശരാശരി ചതുര വ്യതിയാനത്തിന് തുല്യമാണ്. ചെയ്തത്ഈ ഗ്രൂപ്പിന്റെ ഗണിത ശരാശരിയിൽ നിന്നുള്ള ഒരു ഗ്രൂപ്പിനുള്ളിൽ (ഗ്രൂപ്പ് ശരാശരി) ഓരോ ഗ്രൂപ്പിനും ലളിതമോ തൂക്കമുള്ളതോ ആയ വ്യത്യാസമായി കണക്കാക്കുന്നു: ![]() അഥവാ
അഥവാ ![]() ,
,
ഗ്രൂപ്പിലെ യൂണിറ്റുകളുടെ എണ്ണം എവിടെയാണ്.
ഓരോ ഗ്രൂപ്പിനും ഉള്ളിലെ ഗ്രൂപ്പിലെ വ്യത്യാസങ്ങളെ അടിസ്ഥാനമാക്കി, ഒരാൾക്ക് നിർണ്ണയിക്കാനാകും ഗ്രൂപ്പിനുള്ളിലെ വ്യതിയാനങ്ങളുടെ മൊത്തത്തിലുള്ള ശരാശരി:
.
മൂന്ന് വിസർജ്ജനങ്ങൾ തമ്മിലുള്ള ബന്ധത്തെ വിളിക്കുന്നു വ്യത്യാസങ്ങൾ ചേർക്കുന്നതിനുള്ള നിയമങ്ങൾ, അതനുസരിച്ച് മൊത്തത്തിലുള്ള വ്യത്യാസം ഗ്രൂപ്പുകൾക്കിടയിലുള്ള വ്യത്യാസങ്ങളുടെയും ഗ്രൂപ്പിനുള്ളിലെ വ്യത്യാസങ്ങളുടെ ശരാശരിയുടെയും ആകെത്തുകയ്ക്ക് തുല്യമാണ്:
ഉദാഹരണം. തൊഴിലാളികളുടെ താരിഫ് വിഭാഗത്തിന്റെ (യോഗ്യത) സ്വാധീനം അവരുടെ അധ്വാനത്തിന്റെ ഉൽപാദനക്ഷമതയുടെ തലത്തിൽ പഠിക്കുമ്പോൾ, ഇനിപ്പറയുന്ന ഡാറ്റ ലഭിച്ചു.
പട്ടിക 5 - ശരാശരി മണിക്കൂർ ഔട്ട്പുട്ട് പ്രകാരം തൊഴിലാളികളുടെ വിതരണം.
№ p/p |
നാലാമത്തെ വിഭാഗത്തിലെ തൊഴിലാളികൾ |
അഞ്ചാം വിഭാഗത്തിലെ തൊഴിലാളികൾ |
|||||
ഔട്ട്പുട്ട് |
ഔട്ട്പുട്ട് |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
ഈ ഉദാഹരണത്തിൽ, ഘടകങ്ങളുടെ സവിശേഷതകൾ അനുസരിച്ച് തൊഴിലാളികളെ രണ്ട് ഗ്രൂപ്പുകളായി തിരിച്ചിരിക്കുന്നു എക്സ്- യോഗ്യതകൾ, അവരുടെ റാങ്ക് സ്വഭാവസവിശേഷതകൾ. തത്ഫലമായുണ്ടാകുന്ന സ്വഭാവം-ഉത്പാദനം-അതിന്റെ സ്വാധീനത്തിലും (ഇന്റർഗ്രൂപ്പ് വ്യതിയാനം) മറ്റ് ക്രമരഹിതമായ ഘടകങ്ങൾ (ഇൻട്രാഗ്രൂപ്പ് വ്യത്യാസം) കാരണം വ്യത്യാസപ്പെടുന്നു. മൂന്ന് വ്യതിയാനങ്ങൾ ഉപയോഗിച്ച് ഈ വ്യതിയാനങ്ങൾ അളക്കുക എന്നതാണ് ലക്ഷ്യം: ആകെ, ഗ്രൂപ്പുകൾക്കിടയിൽ, ഗ്രൂപ്പിനുള്ളിൽ. നിർണ്ണയത്തിന്റെ അനുഭവ ഗുണകം, ഫലമായുണ്ടാകുന്ന സ്വഭാവത്തിലെ വ്യതിയാനത്തിന്റെ അനുപാതം കാണിക്കുന്നു ചെയ്തത്ഒരു ഘടകം ചിഹ്നത്തിന്റെ സ്വാധീനത്തിൽ എക്സ്. ആകെയുള്ള വ്യതിയാനത്തിന്റെ ബാക്കി ചെയ്തത്മറ്റ് ഘടകങ്ങളിലെ മാറ്റങ്ങൾ കാരണം.
ഉദാഹരണത്തിൽ, നിർണ്ണയത്തിന്റെ അനുഭവ ഗുണകം: ![]() അല്ലെങ്കിൽ 66.7%,
അല്ലെങ്കിൽ 66.7%,
ഇതിനർത്ഥം തൊഴിലാളികളുടെ ഉൽപ്പാദനക്ഷമതയിലെ 66.7% വ്യത്യാസം യോഗ്യതകളിലെ വ്യത്യാസങ്ങൾ മൂലമാണ്, 33.3% മറ്റ് ഘടകങ്ങളുടെ സ്വാധീനം മൂലമാണ്.
അനുഭവപരമായ പരസ്പരബന്ധംഗ്രൂപ്പിംഗും പ്രകടന സവിശേഷതകളും തമ്മിലുള്ള അടുത്ത ബന്ധം കാണിക്കുന്നു. നിർണ്ണയത്തിന്റെ അനുഭവ ഗുണകത്തിന്റെ വർഗ്ഗമൂലമായി കണക്കാക്കുന്നു:
അനുഭവപരമായ പരസ്പര ബന്ധ അനുപാതം പോലെ, 0 മുതൽ 1 വരെയുള്ള മൂല്യങ്ങൾ എടുക്കാം.
കണക്ഷൻ ഇല്ലെങ്കിൽ, =0. ഈ സാഹചര്യത്തിൽ =0, അതായത്, ഗ്രൂപ്പ് അർത്ഥങ്ങൾ പരസ്പരം തുല്യമാണ്, ഇന്റർഗ്രൂപ്പ് വ്യത്യാസമില്ല. ഇതിനർത്ഥം ഗ്രൂപ്പിംഗ് സ്വഭാവം - ഘടകം പൊതുവായ വ്യതിയാനത്തിന്റെ രൂപീകരണത്തെ ബാധിക്കില്ല എന്നാണ്.
കണക്ഷൻ പ്രവർത്തനക്ഷമമാണെങ്കിൽ, =1. ഈ സാഹചര്യത്തിൽ, ഗ്രൂപ്പ് മാർഗങ്ങളുടെ വ്യത്യാസം മൊത്തം വ്യതിയാനത്തിന് തുല്യമാണ് (), അതായത്, ഗ്രൂപ്പിനുള്ളിൽ വ്യത്യാസമില്ല. ഇതിനർത്ഥം ഗ്രൂപ്പിംഗ് സ്വഭാവം പഠിക്കുന്ന ഫലമായുണ്ടാകുന്ന സ്വഭാവത്തിന്റെ വ്യതിയാനത്തെ പൂർണ്ണമായും നിർണ്ണയിക്കുന്നു എന്നാണ്.
പരസ്പര ബന്ധ അനുപാതത്തിന്റെ മൂല്യം ഐക്യത്തോട് അടുക്കുന്നു, പ്രവർത്തനപരമായ ആശ്രിതത്വത്തോട് അടുക്കുന്നു, സ്വഭാവസവിശേഷതകൾ തമ്മിലുള്ള ബന്ധമാണ്.
സ്വഭാവസവിശേഷതകൾ തമ്മിലുള്ള ബന്ധങ്ങളുടെ അടുപ്പം ഗുണപരമായി വിലയിരുത്തുന്നതിന്, ചാഡോക്കിന്റെ ബന്ധങ്ങൾ ഉപയോഗിക്കുന്നു.
ഉദാഹരണത്തിൽ ![]() , ഇത് തൊഴിലാളികളുടെ ഉൽപ്പാദനക്ഷമതയും അവരുടെ യോഗ്യതകളും തമ്മിലുള്ള അടുത്ത ബന്ധത്തെ സൂചിപ്പിക്കുന്നു.
, ഇത് തൊഴിലാളികളുടെ ഉൽപ്പാദനക്ഷമതയും അവരുടെ യോഗ്യതകളും തമ്മിലുള്ള അടുത്ത ബന്ധത്തെ സൂചിപ്പിക്കുന്നു.
ഗണിത ശരാശരി കണക്കാക്കുന്നതിനുള്ള രീതികൾ (ലളിതമായതും തൂക്കമുള്ളതുമായ ഗണിത ശരാശരി, നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച്)
ഞങ്ങൾ ശരാശരി മൂല്യങ്ങൾ നിർണ്ണയിക്കുന്നു:
മോഡ് (മോ) =11, കാരണം ഈ ഓപ്ഷൻ മിക്കപ്പോഴും വേരിയേഷൻ സീരീസിലാണ് സംഭവിക്കുന്നത് (p = 6).
മീഡിയൻ (ഞാൻ) - മധ്യസ്ഥാനം ഉൾക്കൊള്ളുന്ന വേരിയന്റിന്റെ സീരിയൽ നമ്പർ = 23, വേരിയേഷൻ ശ്രേണിയിലെ ഈ സ്ഥലം 11-ന് തുല്യമായ വേരിയന്റാണ് ഉൾക്കൊള്ളുന്നത്. പഠിക്കുന്ന സ്വഭാവം. ഗണിത ശരാശരി കണക്കാക്കാൻ, രണ്ട് രീതികൾ ഉപയോഗിക്കുന്നു: ഗണിത ശരാശരി രീതിയും നിമിഷങ്ങളുടെ രീതിയും.
വ്യതിയാന ശ്രേണിയിലെ ഓരോ ഓപ്ഷന്റെയും ആവൃത്തി 1 ന് തുല്യമാണെങ്കിൽ, ഗണിത ശരാശരി രീതി ഉപയോഗിച്ച് ലളിതമായ ഗണിത ശരാശരി കണക്കാക്കുന്നു: M = .
ഒരു വ്യതിയാന ശ്രേണിയിൽ ഒരു വേരിയന്റ് സംഭവിക്കുന്നതിന്റെ ആവൃത്തി 1 ൽ നിന്ന് വ്യത്യസ്തമാണെങ്കിൽ, ഗണിത ശരാശരി രീതി ഉപയോഗിച്ച് വെയ്റ്റഡ് ഗണിത ശരാശരി കണക്കാക്കുന്നു:
നിമിഷങ്ങളുടെ രീതി അനുസരിച്ച്: എ - സോപാധിക ശരാശരി,
M = A + =11 += 10.4 d=V-A, A=Mo=11
വേരിയേഷൻ സീരീസിലെ ഓപ്ഷനുകളുടെ എണ്ണം 30-ൽ കൂടുതലാണെങ്കിൽ, ഒരു ഗ്രൂപ്പഡ് സീരീസ് നിർമ്മിക്കപ്പെടും. ഒരു ഗ്രൂപ്പ് സീരീസ് നിർമ്മിക്കുന്നു:
1) Vmin, Vmax എന്നിവയുടെ നിർണ്ണയം Vmin=3, Vmax=20;
2) ഗ്രൂപ്പുകളുടെ എണ്ണം നിർണ്ണയിക്കൽ (പട്ടിക പ്രകാരം);
3) ഗ്രൂപ്പുകൾ തമ്മിലുള്ള ഇടവേളയുടെ കണക്കുകൂട്ടൽ ഞാൻ = 3;
4) ഗ്രൂപ്പുകളുടെ തുടക്കവും അവസാനവും നിർണ്ണയിക്കുന്നു;
5) ഓരോ ഗ്രൂപ്പിന്റെയും വേരിയന്റിന്റെ ആവൃത്തി നിർണ്ണയിക്കൽ (പട്ടിക 2).
പട്ടിക 2
ഒരു ഗ്രൂപ്പ് സീരീസ് നിർമ്മിക്കുന്നതിനുള്ള രീതിശാസ്ത്രം
|
ദൈർഘ്യം ദിവസങ്ങളിൽ ചികിത്സ |
|||||||
|
n=45 p=480 p=30 2 p=766 |
ഒരു ഗ്രൂപ്പുചെയ്ത വ്യതിയാന പരമ്പരയുടെ പ്രയോജനം, ഗവേഷകൻ എല്ലാ ഓപ്ഷനുകളിലും പ്രവർത്തിക്കുന്നില്ല, എന്നാൽ ഓരോ ഗ്രൂപ്പിനും ശരാശരിയുള്ള ഓപ്ഷനുകളിൽ മാത്രം പ്രവർത്തിക്കുന്നു എന്നതാണ്. ഇത് ശരാശരിയുടെ കണക്കുകൂട്ടലുകൾ വളരെ ലളിതമാക്കുന്നു.
ഒരു പ്രത്യേക സ്വഭാവത്തിന്റെ മൂല്യം ജനസംഖ്യയിലെ എല്ലാ അംഗങ്ങൾക്കും തുല്യമല്ല, അതിന്റെ ആപേക്ഷിക ഏകത ഉണ്ടായിരുന്നിട്ടും. സ്റ്റാറ്റിസ്റ്റിക്കൽ പോപ്പുലേഷന്റെ ഈ സവിശേഷത സാധാരണ ജനസംഖ്യയുടെ ഗ്രൂപ്പ് പ്രോപ്പർട്ടികളിലൊന്നാണ് - സ്വഭാവ വൈവിധ്യം. ഉദാഹരണത്തിന്, നമുക്ക് 12 വയസ്സുള്ള ആൺകുട്ടികളുടെ ഒരു കൂട്ടം എടുത്ത് അവരുടെ ഉയരം അളക്കാം. കണക്കുകൂട്ടലുകൾക്ക് ശേഷം, ഈ സ്വഭാവത്തിന്റെ ശരാശരി ലെവൽ 153 സെന്റീമീറ്റർ ആയിരിക്കും.എന്നാൽ ശരാശരി, പഠിക്കുന്ന സ്വഭാവത്തിന്റെ പൊതുവായ അളവാണ്. ഒരു നിശ്ചിത പ്രായത്തിലുള്ള ആൺകുട്ടികളിൽ, 165 സെന്റീമീറ്റർ അല്ലെങ്കിൽ 141 സെന്റീമീറ്റർ ഉയരമുള്ള ആൺകുട്ടികൾ ഉണ്ട്.കൂടുതൽ ആൺകുട്ടികൾക്ക് 153 സെന്റിമീറ്ററിൽ കൂടുതൽ ഉയരമുണ്ട്, സ്റ്റാറ്റിസ്റ്റിക്കൽ ജനസംഖ്യയിൽ ഈ സ്വഭാവത്തിന്റെ വൈവിധ്യം വർദ്ധിക്കും.
സ്ഥിതിവിവരക്കണക്കുകൾ ഇനിപ്പറയുന്ന മാനദണ്ഡങ്ങളാൽ ഈ പ്രോപ്പർട്ടി വിശേഷിപ്പിക്കാൻ ഞങ്ങളെ അനുവദിക്കുന്നു:
പരിധി (ലിം),
വ്യാപ്തി (Amp),
സ്റ്റാൻഡേർഡ് ഡീവിയേഷൻ ( y) ,
കോഫിഫിഷ്യന്റ് ഓഫ് വേരിയേഷൻ (സിവി).
പരിധിവ്യതിയാന ശ്രേണിയിലെ വേരിയന്റിന്റെ അങ്ങേയറ്റത്തെ മൂല്യങ്ങളാൽ നിർണ്ണയിക്കപ്പെടുന്നു:
lim=V മിനിറ്റ് /V പരമാവധി
ആംപ്ലിറ്റ്യൂഡ് (Amp) -അങ്ങേയറ്റത്തെ ഓപ്ഷനുകൾ തമ്മിലുള്ള വ്യത്യാസം:
Amp=V max -V മിനിറ്റ്
ഈ മൂല്യങ്ങൾ അങ്ങേയറ്റത്തെ വകഭേദങ്ങളുടെ വൈവിധ്യത്തെ മാത്രം കണക്കിലെടുക്കുന്നു, കൂടാതെ അതിന്റെ ആന്തരിക ഘടന കണക്കിലെടുത്ത് മൊത്തത്തിൽ ഒരു സ്വഭാവത്തിന്റെ വൈവിധ്യത്തെക്കുറിച്ചുള്ള വിവരങ്ങൾ നേടാൻ ഒരാളെ അനുവദിക്കുന്നില്ല. അതിനാൽ, ഈ മാനദണ്ഡങ്ങൾ ഏകദേശ വൈവിധ്യ സ്വഭാവസവിശേഷതകൾക്കായി ഉപയോഗിക്കാം, പ്രത്യേകിച്ച് ചെറിയ എണ്ണം നിരീക്ഷണങ്ങൾ (n<30).
വ്യതിയാന പരമ്പര മെഡിക്കൽ സ്ഥിതിവിവരക്കണക്കുകൾ
എ - സോപാധിക ശരാശരി (വ്യതിയാന ശ്രേണിയിലെ മറ്റുള്ളവയേക്കാൾ കൂടുതൽ തവണ ആവർത്തിക്കുന്നു)
a - സോപാധിക ശരാശരിയിൽ നിന്ന് സോപാധിക വ്യതിയാനം (റാങ്ക്)
i - ഇടവേള
ഘട്ടം 1 - ഗ്രൂപ്പുകളുടെ മധ്യഭാഗം നിർണ്ണയിക്കുന്നു;
ഘട്ടം 2 - ഗ്രൂപ്പുകളുടെ റാങ്കിംഗ്: വേരിയന്റിന്റെ ആവൃത്തി ഏറ്റവും കൂടുതലുള്ള ഗ്രൂപ്പിന് 0 നൽകിയിട്ടുണ്ട്. ആ. ഈ സാഹചര്യത്തിൽ 7-11 (ആവൃത്തി -32). തന്നിരിക്കുന്ന ഗ്രൂപ്പിൽ നിന്ന് മുകളിലേക്ക് റാങ്ക് ചെയ്യുന്നത് (-1) ചേർത്താണ് ചെയ്യുന്നത്. താഴേക്ക് - വർദ്ധിപ്പിക്കുക (+1).
ഘട്ടം 3 - സോപാധിക മോഡിന്റെ നിർണ്ണയം (സോപാധിക ശരാശരി). മോഡൽ ഇടവേളയുടെ മധ്യഭാഗമാണ് എ. ഞങ്ങളുടെ കാര്യത്തിൽ, മോഡൽ ഇടവേള 7 -11 ആണ്, അതിനാൽ A = 9.
ഘട്ടം 4 - ഇടവേള നിർണ്ണയിക്കുന്നു. പരമ്പരയിലെ എല്ലാ ഗ്രൂപ്പുകളിലെയും ഇടവേള ഒന്നുതന്നെയും 5 ന് തുല്യവുമാണ്. i = 5/
ഘട്ടം 5 - നിരീക്ഷണങ്ങളുടെ ആകെ എണ്ണം നിർണ്ണയിക്കൽ. n = ∑p = 103.
ലഭിച്ച ഡാറ്റ ഞങ്ങൾ ഫോർമുലയിലേക്ക് മാറ്റിസ്ഥാപിക്കുന്നു:
സ്വതന്ത്ര ജോലിക്കുള്ള ചുമതലകൾ
ഗ്രൂപ്പുചെയ്ത വ്യതിയാന ശ്രേണിയിൽ നിന്നുള്ള ഡാറ്റ ഉപയോഗിച്ച്, നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് ഗണിത ശരാശരി കണക്കാക്കുക.
ഓപ്ഷൻ 1
ഓപ്ഷൻ നമ്പർ 2
ഓപ്ഷൻ #3
ഓപ്ഷൻ നമ്പർ 4
ഓപ്ഷൻ #5
ഓപ്ഷൻ #6
ഓപ്ഷൻ നമ്പർ 7
ഓപ്ഷൻ നമ്പർ 8
ഓപ്ഷൻ നമ്പർ 9
ഓപ്ഷൻ നമ്പർ 10
ഓപ്ഷൻ നമ്പർ 11
ഓപ്ഷൻ നമ്പർ 12
ടാസ്ക് നമ്പർ 4 ഒറ്റസംഖ്യ ഓപ്ഷനുകളുള്ള ഗ്രൂപ്പുചെയ്യാത്ത വേരിയേഷൻ സീരീസിലെ മോഡും മീഡിയനും നിർണ്ണയിക്കുന്നു
രോഗബാധിതരായ കുട്ടികളുടെ ഇൻപേഷ്യന്റ് ചികിത്സയുടെ ദൈർഘ്യം: 15, 14, 18, 17, 16, 20, 19, 16, 14, 16, 17, 12, 18, 19, 20.
ഒരു വേരിയേഷൻ സീരീസിലെ മോഡ് നിർണ്ണയിക്കാൻ, സീരീസ് റാങ്കിംഗ് ആവശ്യമില്ല. എന്നിരുന്നാലും, മീഡിയൻ നിർണ്ണയിക്കുന്നതിന് മുമ്പ്, ആരോഹണ അല്ലെങ്കിൽ അവരോഹണ ക്രമത്തിൽ വ്യതിയാന ശ്രേണി ക്രമീകരിക്കേണ്ടത് ആവശ്യമാണ്.
12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20.
മോഡ് = 16. കാരണം ഓപ്ഷൻ 16 ആണ് ഏറ്റവും കൂടുതൽ തവണ സംഭവിക്കുന്നത് (3 തവണ).
സംഭവങ്ങളുടെ ഏറ്റവും ഉയർന്ന ആവൃത്തിയുള്ള നിരവധി വകഭേദങ്ങൾ ഉണ്ടെങ്കിൽ, വേരിയേഷൻ ശ്രേണിയിൽ രണ്ടോ അതിലധികമോ മോഡുകൾ സൂചിപ്പിക്കാം.
ഒറ്റ സംഖ്യയുള്ള ഒരു ശ്രേണിയിലെ മീഡിയൻ ഫോർമുലയാൽ നിർണ്ണയിക്കപ്പെടുന്നു: 
റാങ്ക് ചെയ്ത വ്യതിയാന ശ്രേണിയിലെ മീഡിയന്റെ സീരിയൽ നമ്പറാണ് 8,
അത്. ഞാൻ = 17.
ടാസ്ക് നമ്പർ 5 ഇരട്ടി എണ്ണം ഓപ്ഷനുകളുള്ള ഗ്രൂപ്പ് ചെയ്യാത്ത വേരിയേഷൻ സീരീസിൽ മോഡും മീഡിയനും നിർണ്ണയിക്കുന്നു.
ടാസ്ക്കിൽ നൽകിയിരിക്കുന്ന ഡാറ്റയെ അടിസ്ഥാനമാക്കി, നിങ്ങൾ മോഡും മീഡിയനും കണ്ടെത്തേണ്ടതുണ്ട്
രോഗബാധിതരായ കുട്ടികളുടെ ഇൻപേഷ്യന്റ് ചികിത്സയുടെ ദൈർഘ്യം: 15, 14, 18, 17, 16, 20, 19, 16, 14, 16, 17, 12, 18, 19, 20, 11
ഞങ്ങൾ ഒരു റാങ്ക് വ്യതിയാന പരമ്പര നിർമ്മിക്കുന്നു:
11, 12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20
നമുക്ക് രണ്ട് മീഡിയൻ സംഖ്യകൾ 16 ഉം 17 ഉം ഉണ്ട്. ഈ സാഹചര്യത്തിൽ, അവയ്ക്കിടയിലുള്ള ഗണിത ശരാശരിയായി മീഡിയൻ കാണപ്പെടുന്നു. ഞാൻ = 16.5.
4. ഇരട്ടയും ഒറ്റയും.
ഇരട്ട വ്യതിയാന ശ്രേണിയിൽ, ആവൃത്തികളുടെ ആകെത്തുക അല്ലെങ്കിൽ നിരീക്ഷണങ്ങളുടെ ആകെ എണ്ണം ഇരട്ട സംഖ്യയാൽ പ്രകടിപ്പിക്കുന്നു, ഒറ്റസംഖ്യയിൽ - ഒറ്റ സംഖ്യ കൊണ്ട്.
5. സമമിതിയും അസമത്വവും.
ഒരു സമമിതി വ്യതിയാന ശ്രേണിയിൽ, എല്ലാത്തരം ശരാശരി മൂല്യങ്ങളും യോജിക്കുന്നു അല്ലെങ്കിൽ വളരെ അടുത്താണ് (മോഡ്, മീഡിയൻ, ഗണിത ശരാശരി).
പഠിക്കുന്ന പ്രതിഭാസങ്ങളുടെ സ്വഭാവത്തെ ആശ്രയിച്ച്, സ്റ്റാറ്റിസ്റ്റിക്കൽ ഗവേഷണത്തിന്റെ നിർദ്ദിഷ്ട ചുമതലകളും ലക്ഷ്യങ്ങളും, അതുപോലെ തന്നെ സാനിറ്ററി സ്റ്റാറ്റിസ്റ്റിക്സിലെ ഉറവിട മെറ്റീരിയലിന്റെ ഉള്ളടക്കവും ഇനിപ്പറയുന്ന തരത്തിലുള്ള ശരാശരികൾ ഉപയോഗിക്കുന്നു:
· ഘടനാപരമായ ശരാശരി (മോഡ്, മീഡിയൻ);
· ഗണിത ശരാശരി;
· ഹാർമോണിക് അർത്ഥം;
· ജ്യാമിതീയ അർത്ഥം;
· ഇടത്തരം പുരോഗമന.
ഫാഷൻ (എം ഒ) - ഒരു വ്യത്യസ്ത സ്വഭാവസവിശേഷതയുടെ മൂല്യം, അത് പഠിക്കപ്പെടുന്ന ജനസംഖ്യയിൽ കൂടുതലായി കാണപ്പെടുന്നു, അതായത്. ഏറ്റവും ഉയർന്ന ആവൃത്തിയുമായി ബന്ധപ്പെട്ട ഓപ്ഷൻ. ഒരു കണക്കുകൂട്ടലിലും അവലംബിക്കാതെ, വ്യതിയാന ശ്രേണിയുടെ ഘടനയിൽ നിന്ന് അവർ അത് നേരിട്ട് കണ്ടെത്തുന്നു. ഇത് സാധാരണയായി ഗണിത ശരാശരിയോട് വളരെ അടുത്തുള്ള ഒരു മൂല്യമാണ്, ഇത് പ്രായോഗികമായി വളരെ സൗകര്യപ്രദവുമാണ്.
മീഡിയൻ (എം ഇ) - വേരിയേഷൻ സീരീസ് (റാങ്ക് ചെയ്തത്, അതായത് ഓപ്ഷന്റെ മൂല്യങ്ങൾ ആരോഹണ അല്ലെങ്കിൽ അവരോഹണ ക്രമത്തിൽ ക്രമീകരിച്ചിരിക്കുന്നു) രണ്ട് തുല്യ പകുതികളായി വിഭജിക്കുന്നു. ആവൃത്തികളുടെ ക്രമാനുഗതമായ സംഗ്രഹം വഴി ലഭിക്കുന്ന വിചിത്ര ശ്രേണികൾ ഉപയോഗിച്ചാണ് മീഡിയൻ കണക്കാക്കുന്നത്. ആവൃത്തികളുടെ ആകെത്തുക ഒരു ഇരട്ട സംഖ്യയുമായി യോജിക്കുന്നുവെങ്കിൽ, രണ്ട് ശരാശരി മൂല്യങ്ങളുടെ ഗണിത ശരാശരി പരമ്പരാഗതമായി ശരാശരിയായി കണക്കാക്കുന്നു.
ഒരു തുറന്ന ജനസംഖ്യയുടെ കാര്യത്തിൽ മോഡും മീഡിയനും ഉപയോഗിക്കുന്നു, അതായത്. ഏറ്റവും വലുതോ ചെറുതോ ആയ ഓപ്ഷനുകൾക്ക് കൃത്യമായ അളവ് സ്വഭാവം ഇല്ലെങ്കിൽ (ഉദാഹരണത്തിന്, 15 വയസ്സ് വരെ, 50 വയസും അതിൽ കൂടുതലും, മുതലായവ). ഈ സാഹചര്യത്തിൽ, ഗണിത ശരാശരി (പാരാമെട്രിക് സവിശേഷതകൾ) കണക്കാക്കാൻ കഴിയില്ല.
ശരാശരി ഞാൻ ഗണിതക്കാരനാണ് - ഏറ്റവും സാധാരണമായ മൂല്യം. ഗണിത ശരാശരി പലപ്പോഴും സൂചിപ്പിക്കുന്നത് എം.
ലളിതവും ഭാരമുള്ളതുമായ ഗണിത ശരാശരികളുണ്ട്.
ലളിതമായ ഗണിത ശരാശരി കണക്കാക്കിയത്:
- ഓരോ യൂണിറ്റിനും ഒരു സ്വഭാവസവിശേഷതയെക്കുറിച്ചുള്ള അറിവിന്റെ ലളിതമായ ലിസ്റ്റ് ജനസംഖ്യയെ പ്രതിനിധീകരിക്കുന്ന സന്ദർഭങ്ങളിൽ;
- ഓരോ ഓപ്ഷന്റെയും ആവർത്തനങ്ങളുടെ എണ്ണം നിർണ്ണയിക്കാൻ കഴിയുന്നില്ലെങ്കിൽ;
- ഓരോ ഓപ്ഷന്റെയും ആവർത്തനങ്ങളുടെ എണ്ണം പരസ്പരം അടുത്താണെങ്കിൽ.
ലളിതമായ ഗണിത ശരാശരി ഫോർമുല ഉപയോഗിച്ച് കണക്കാക്കുന്നു:
എവിടെ V - സ്വഭാവത്തിന്റെ വ്യക്തിഗത മൂല്യങ്ങൾ; n - വ്യക്തിഗത മൂല്യങ്ങളുടെ എണ്ണം; - സംഗ്രഹ ചിഹ്നം.
അങ്ങനെ, ലളിതമായ ശരാശരി എന്നത് വേരിയന്റുകളുടെ ആകെത്തുകയും നിരീക്ഷണങ്ങളുടെ എണ്ണവും തമ്മിലുള്ള അനുപാതമാണ്.
ഉദാഹരണം: ന്യുമോണിയ ബാധിച്ച 10 രോഗികൾക്ക് ഒരു കിടക്കയിൽ താമസിക്കുന്നതിന്റെ ശരാശരി ദൈർഘ്യം നിർണ്ണയിക്കുക:
16 ദിവസം - 1 രോഗി; 17–1; 18-1; 19–1; 20-1; 21-1; 22-1; 23-1; 26-1; 31-1.
ബെഡ്-ഡേ
ഗണിത ശരാശരി തൂക്കം ഒരു സ്വഭാവത്തിന്റെ വ്യക്തിഗത മൂല്യങ്ങൾ ആവർത്തിക്കുന്ന സന്ദർഭങ്ങളിൽ കണക്കാക്കുന്നു. ഇത് രണ്ട് തരത്തിൽ കണക്കാക്കാം:
1. ഫോർമുല അനുസരിച്ച് നേരിട്ട് (ഗണിത ശരാശരി അല്ലെങ്കിൽ നേരിട്ടുള്ള രീതി):
ഇവിടെ P എന്നത് ഓരോ ഓപ്ഷന്റെയും നിരീക്ഷണങ്ങളുടെ ആവൃത്തി (കേസുകളുടെ എണ്ണം) ആണ്.
അങ്ങനെ, വെയ്റ്റഡ് ഗണിത ശരാശരി എന്നത് വേരിയന്റിന്റെയും ആവൃത്തിയുടെയും ഉൽപ്പന്നങ്ങളുടെ ആകെത്തുക നിരീക്ഷണങ്ങളുടെ എണ്ണത്തിലേക്കുള്ള അനുപാതമാണ്.
2. സോപാധിക ശരാശരിയിൽ നിന്നുള്ള വ്യതിയാനങ്ങൾ കണക്കാക്കുന്നതിലൂടെ (നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച്).
തൂക്കമുള്ള ഗണിത ശരാശരി കണക്കാക്കുന്നതിനുള്ള അടിസ്ഥാനം:
- ഒരു അളവ് സ്വഭാവത്തിന്റെ വകഭേദങ്ങൾ അനുസരിച്ച് ഗ്രൂപ്പ് ചെയ്ത മെറ്റീരിയൽ;
— എല്ലാ ഓപ്ഷനുകളും ആട്രിബ്യൂട്ടിന്റെ മൂല്യത്തിന്റെ ആരോഹണ അല്ലെങ്കിൽ അവരോഹണ ക്രമത്തിൽ ക്രമീകരിക്കണം (റാങ്ക് ചെയ്ത വരി).
മൊമെന്റ് രീതി ഉപയോഗിച്ച് കണക്കുകൂട്ടാൻ, ഒരു മുൻവ്യവസ്ഥ എല്ലാ ഇടവേളകളുടെയും ഒരേ വലുപ്പമാണ്.
നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച്, ഫോർമുല ഉപയോഗിച്ച് ഗണിത ശരാശരി കണക്കാക്കുന്നു:
 ,
,
ഇവിടെ Mo എന്നത് സോപാധികമായ ശരാശരിയാണ്, അത് പലപ്പോഴും ഉയർന്ന ആവൃത്തിയുമായി ബന്ധപ്പെട്ട സ്വഭാവത്തിന്റെ മൂല്യമായി കണക്കാക്കപ്പെടുന്നു, അതായത്. ഇത് കൂടുതൽ തവണ ആവർത്തിക്കുന്നു (ഫാഷൻ).
i ആണ് ഇടവേളയുടെ മൂല്യം.
a എന്നത് ശരാശരിയുടെ വ്യവസ്ഥകളിൽ നിന്നുള്ള ഒരു സോപാധിക വ്യതിയാനമാണ്, ഇത് വലിയ സോപാധിക ശരാശരികളുടെ വകഭേദങ്ങൾക്ക് + ചിഹ്നവും ഒരു - ചിഹ്നവും (-1, -2, മുതലായവ) ഉള്ള സംഖ്യകളുടെ (1, 2, മുതലായവ) ഒരു തുടർച്ചയായ ശ്രേണിയാണ്. .) പരമ്പരാഗത ശരാശരിയേക്കാൾ താഴെയുള്ള വേരിയന്റുകൾക്ക്. സോപാധിക ശരാശരിയായി എടുത്ത വേരിയന്റിൽ നിന്നുള്ള സോപാധിക വ്യതിയാനം 0 ആണ്.
പി - ആവൃത്തികൾ.
നിരീക്ഷണങ്ങളുടെ ആകെ എണ്ണം അല്ലെങ്കിൽ n.
ഉദാഹരണം: 8 വയസ്സുള്ള ആൺകുട്ടികളുടെ ശരാശരി ഉയരം നേരിട്ട് നിർണ്ണയിക്കുക (പട്ടിക 1).
പട്ടിക 1
|
ഉയരം സെ.മീ |
ആൺകുട്ടികൾ പി |
സെൻട്രൽ ഓപ്ഷൻ വി |
|
കേന്ദ്ര ഓപ്ഷൻ - ഇടവേളയുടെ മധ്യഭാഗം - രണ്ട് അയൽ ഗ്രൂപ്പുകളുടെ പ്രാരംഭ മൂല്യങ്ങളുടെ അർദ്ധ തുകയായി നിർവചിച്ചിരിക്കുന്നു:
![]() ;
; ![]() തുടങ്ങിയവ.
തുടങ്ങിയവ.
സെൻട്രൽ വേരിയന്റുകളെ ഫ്രീക്വൻസികൾ കൊണ്ട് ഗുണിച്ചാണ് ഉൽപ്പന്ന VP ലഭിക്കുന്നത്; തുടങ്ങിയവ. അപ്പോൾ തത്ഫലമായുണ്ടാകുന്ന ഉൽപ്പന്നങ്ങൾ കൂട്ടിച്ചേർക്കുകയും നേടുകയും ചെയ്യുന്നു ![]() , ഇത് നിരീക്ഷണങ്ങളുടെ എണ്ണം കൊണ്ട് ഹരിച്ചാൽ (100) ഒരു വെയ്റ്റഡ് ഗണിത ശരാശരി ലഭിക്കും.
, ഇത് നിരീക്ഷണങ്ങളുടെ എണ്ണം കൊണ്ട് ഹരിച്ചാൽ (100) ഒരു വെയ്റ്റഡ് ഗണിത ശരാശരി ലഭിക്കും.
![]() സെമി.
സെമി.
നിമിഷങ്ങളുടെ രീതി ഉപയോഗിച്ച് ഞങ്ങൾ അതേ പ്രശ്നം പരിഹരിക്കും, ഇതിനായി ഇനിപ്പറയുന്ന പട്ടിക 2 സമാഹരിച്ചിരിക്കുന്നു:
പട്ടിക 2
|
ഉയരം സെന്റിമീറ്ററിൽ (V) |
ആൺകുട്ടികൾ പി |
||
ഞങ്ങൾ 122 എം ഒ ആയി എടുക്കുന്നു, കാരണം 100 നിരീക്ഷണങ്ങളിൽ 33 പേർക്ക് 122 സെന്റീമീറ്റർ ഉയരമുണ്ട്. മുകളിൽ പറഞ്ഞവയ്ക്ക് അനുസൃതമായി സോപാധിക ശരാശരിയിൽ നിന്ന് സോപാധികമായ വ്യതിയാനങ്ങൾ (എ) ഞങ്ങൾ കണ്ടെത്തുന്നു. അപ്പോൾ ഞങ്ങൾ സോപാധിക വ്യതിയാനങ്ങളുടെയും ആവൃത്തികളുടെയും (എപി) ഉൽപ്പന്നം നേടുകയും ലഭിച്ച മൂല്യങ്ങൾ () സംഗ്രഹിക്കുകയും ചെയ്യുന്നു. ഫലം 17. അവസാനമായി, ഞങ്ങൾ ഫോർമുലയിലേക്ക് ഡാറ്റ മാറ്റിസ്ഥാപിക്കുന്നു.